Understanding Transformer
Why, What, How of Transformer
Understanding Transformer
Why, What, How of Transformer

Photo by Google DeepMind on Unsplash
What is a transformer?
A transformer is a neural network that can learn the relationship between words in a sentence. It does this by using a mechanism called self-attention. Self-attention allows the transformer to look at all the words in a sentence and learn how they relate. This is important for tasks like machine translation and text summarization, where it is essential to understand the meaning of a sentence as a whole.
Why transformer is a game changer?
The transformer architecture was first introduced in the paper “Attention is All You Need” by Vaswani et al. (2017). The paper showed that transformers could achieve state-of-the-art results on various natural language processing tasks and the potential to revolutionize the way we interact with computers.
Transformers are very effective as they can learn long-range dependencies between words in a sentence and are relatively simple to train.
Transformers can be used for a variety of NLP tasks,
- Machine translation
- Text summarization
- Question answering
- Natural language inference
- Text generation
- Code generation
- Speech recognition
- Image captioning
How do transformers work?
Let us understand how transformers work using the text example “How are you.”
The four main parts of an AI transformer are:
- Embedding layer: This layer converts the input text into a sequence of vectors.
- Attention layer: This layer learns the relationship between the words in the input text.
- Feed-forward layer: This layer applies a non-linear transformation to the output of the attention layer.
- Output layer: This layer generates the output text.

Embedding layer:
a. The input text is tokenized. This means that the text is broken down into individual words or subwords.
https://platform.openai.com/tokenizer

b. Each token is looked up in a vocabulary. The vocabulary is a list of all the words or subwords on which the transformer has been trained.

c. The token index in the vocabulary is used to look up the corresponding embedding vector. The embedding vector is a fixed-length vector representing the token's meaning.
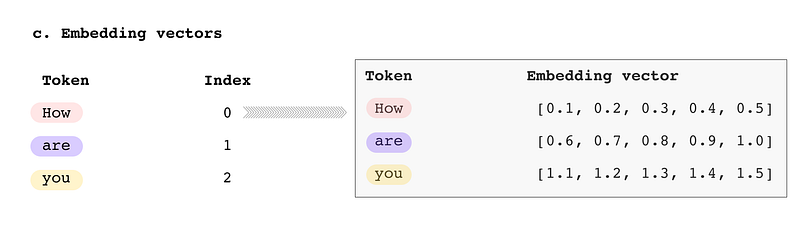
d. The embedding vectors for all the tokens in the input text are concatenated together. This creates a single vector that represents the entire input text.

The vector is then passed to the attention layer of the transformer.
Attention layer:
a. The input vector is split into a query vector and a key vector. The query vector represents the current position in the input text. The key vector represents all the other positions in the input text.

In this example, the input vector is a 10-dimensional vector representing the entire input text. The query vector is a 5-dimensional vector representing the input text's current position. The key vector is a 5-dimensional vector that represents all the other positions in the input text.
b. The query vector and the key vector are multiplied together. This creates a matrix of scores.

In this example, the query and key vectors are both 5-dimensional vectors. The query vector represents the current position in the input text. The key vector represents all the other positions in the input text. The query and key vectors are multiplied to create a scoring matrix. The scores represent the importance of each position in the input text relative to the current position.
c. The scores are normalized. This means that the scores are all scaled to have a sum of 1.

In this example, the matrix of scores is normalized by dividing each score by the sum of all the scores. This ensures that the scores all have a sum of 1. The normalized scores represent the importance of each position in the input text relative to the current position after being normalized.
d. The normalized scores create a weighted sum of the key vectors. This weighted sum is called the attention vector.

In this example, the attention weights show that “are” is most important to the word “you.” This is because the word “are” is the closest word to the word “you” in the input text. The attention layer then uses these weights to create a weighted sum of the key vectors. This weighted sum is called the attention vector.
e. The attention vector is then added to the query vector. This creates a new vector that represents the current position in the input text, considering the importance of all the other positions in the input text.
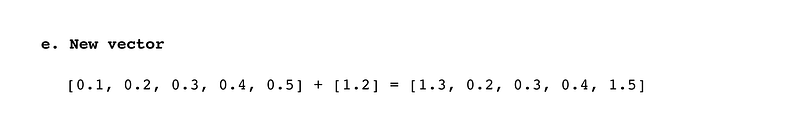
The attention vector is then added to the query vector. This creates a new vector representing the position of the word “are” in the input text, considering the importance of all the other positions in the input text.
The new vector is then passed to the Feed-forward layer of the transformer.
Feed-forward layer:
a. The input vector is multiplied by a weight matrix.

In this example, the input vector is multiplied by the weight matrix element-wise. The result is a new vector with the exact dimensions as the weight matrix. The multiplication output can then be used as input to another layer in the neural network.
b. The product is added to a bias vector.

In this example, the product of the input vector and the weight matrix is added to the bias vector element-wise. The result is a new vector with the exact dimensions as the bias vector.
c. The result is passed through an activation function.

In this example, the result of the addition is passed through the ReLU activation function. The ReLU function returns 0 for any input value less than or equal to 0 and returns the input value for any input value greater than 0. The output of the ReLU function is a new vector with the exact dimensions as the input vector.
The output of the activation function is the output of the feed-forward layer passed on to the Output layer.
Output layer:
- The output of the previous layer is passed to the output layer.
- The output layer has several neurons equal to the number of classes in the problem.
- Each neuron in the output layer has a weight vector and a bias.
- The output of each neuron is calculated by multiplying the input vector by the weight vector and adding the bias.
- The output of each neuron is then passed through an activation function.
- The output of the activation function is the output of the output layer.

In this example, the input vector is passed to the output layer. The output layer has five neurons, one for each class. Each neuron has a weight vector and a bias. The output of each neuron is calculated by multiplying the input vector by the weight vector and adding the bias. The output of each neuron is then passed through the softmax activation function. The softmax function normalizes the output of each neuron so that the sum of all the outputs is equal to 1. The output of the softmax function is the probability that the input belongs to each class.
The output layer predicts the input class in a classification problem. The class with the highest probability is the predicted class.
The output layer is a critical part of a neural network. It is responsible for taking the previous layer's output and converting it into a prediction or a new output. The type of output layer used depends on the task the neural network is being trained to perform.
Note: This article captures my learning notes from understanding the Transformers. I used Bard for this learning purpose.